- 논문 제목: LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
- 저자: Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
- 연도: 2024
- 학회/저널: COLM
- TL;DR: decoder-only LLM을 강력한 text embedding model로 변환하는 간단한 method LLM2Vec 제안
Abstract
- openreview에서 "secretly"하다고 말할 수 없지 않냐고 지적한 게 인상적이었던 논문..
- "It can hardly be considered a secret that LLM can be strong embedding models"
- LLM은 NLP tasks와 benchmarks에서 SOTA models을 달성
- community는 rich contextualized representations가 필요한 text embedding 작업에 이러한 모델을 천천히 채택 중
- LLM2Vec은 세 가지의 간단한 단계로 구성
1. enabling bidirectional attention
2. masked next token prediction
3. unsupervised contrastive learning
- 1.3B에서 7B 파라미터에 이르는 3개의 popular LLMs에 LLM2Vec을 적용하여 효율성을 입증
- 영어 단어 및 시퀀스 수준의 작업에 대한 transformed models을 평가
Introduction
- text embedding model은 자연어 텍스트의 의미적 내용을 벡터 표현으로 enoding
- for 의미적 텍스트 유사성 계산, 정보 검색, 클러스터링과 같은 다양한 NLP 작업 수행
- 이전에는 이러한 모델을 구축하는 데 BERT, T5와 같은 사전학습된 bidirectional encoder 또는 encoder-decoder에 의존
- BERT-like models은 retrieval과 같은 작업에도 적용되며, 최근에는 범용성을 위한 instructions을 사용하여 text embedding(TART, 2023)
- 주요 패러다임은 weakly- and fully-supervised contrastive training으로 구성된 여러 단계의 파이프라인을 따라 text embedding에 적용
- related work-encoder embedding models
- LargeDual EncodersAreGeneralizableRetrievers(2022)

- Pre-training Stage, Fine-Tuning Stage로 multi-step 구조
- Pre-training Stage: T5 Encoder 이용하여 web-mined corpus로 사전학습
- Fine-Tuning Stage: MSMARCO, NQ 데이터(high quality search corpus)
- SimCSE(2021)
- Unsupervised Method로는 주로 Contrastive Learning을 이용
- 동일한 문장에 대하여 서로 다른 dropout masks를 적용 → 두 가지의 다른 representations를 생성

- labled된 데이터가 필요 없고, 간단한 방식(dropout)으로 positive sample 생성 가능
- 그렇다면 왜 Decoder-Only Models로 Text Embedding을 할까?
- 사전학습에서 Decoder-Only LLMs은 모든 입력 토큰에서 학습하므로 동일한 양의 학습데이터에서 높은 sample-efficient
- *sample-efficient: 적은 샘플로도 높은 성능 달성 가능
- “not just a small percentage”— Encoder-only models are typically pre-trained by masking 15% ofthe tokens in the input sequence(Devlin et al.,2019)
- 논문에서는 위와 같이 언급하고는 있으나, encoder-model, 즉 BERT가 전체 데이터의 15%를 masking하여 학습을 한다고 해서 BERT가 15% 데이터만 학습한다고 할 수 없음
- <Should You Mask 15% in Masked Language Modeling?> 논문에 따르면, masking을 80%까지 해도 성능이 높았다고 함
- 이는 masking을 15% 하여도 80%한 것과 비교했을 때 경쟁력이 있고, 따라서 masking을 한다고 해서 데이터의 효율성이 떨어진다고는 하기 부족함

- (각설하고...) decoder-only model은 이러한 모델을 중심으로 검증된 사전학습 방법등이 포함된 rich echo system이 존재
- Instruction fine-tuning 및 human preferences 학습에 대한 최근 연구로 Decoder-only LLMs의 높은 성능 달성
- instruction을 사용하여 다양한 작업을 일반화하는 범용적인 텍스트 임베딩 모델을 구축
- 대표적인 Decoder Embedding Models
- E5-Mistral-7B
- Improving Text Embeddingswith Large Language Models(2023)
- 기존 방식은 2-step Training으로, manually collected datasets에 의존 → task나 language diversity 부족
- 제안 방법
- 1. Text Pair 데이터셋을 LLM으로 생성하여 LLM 학습
- 2. Text Embedding도 LLM으로 구축
- Synthetic Data Generation
- task를 asymmetric, symmetric으로 분리하여 다른 프롬프트 사용
- brainstroming을 통해 LLM이 task에 대한 Instruction을 생성하도록 하고 이를 이용하여 Query-Document 생성

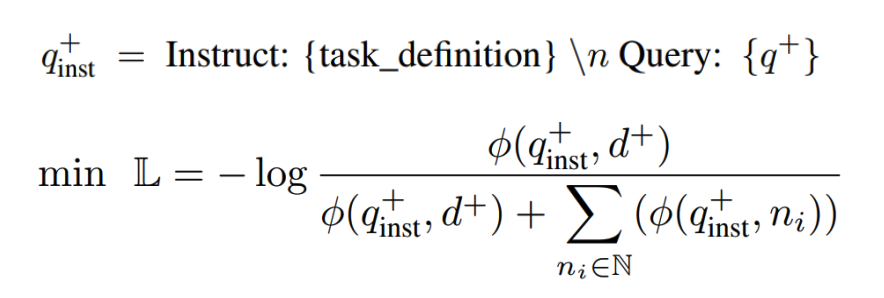
- Echo Embeddings
- Repetition Improves Language Model Embeddings(2024)
- causal attention mechanism은 decoder-only LLMs이 text embedding tasks에서 적용이 느린 이유
- input sequence를 복제하여 바로 뒤에 연결이 되도록 concat → can attend to "future" tokens

- "She loves summers"와 같이 문장의 prefix가 동일한 경우, 전혀 다른 성격의 문장임에도 embedding이 유사해지는 문제를 해결
Method
- 기존에 있는 3가지의 방법을 통합

1. Enabling bidirectional attention
- Decoder-only LLM의 CausalAttention Mask를 All-Ones Matrix로대체
- 이를 통해 각 토큰은 시퀀스의 다른 모든 토큰에 대해 접근 가능
2. Masked Next Token Prediction
- MNTP: 모델이 bidirectional attention을 인식하도록 함
- $x = (x1, . . . , xN)$을 입력으로 받으면 입력 토큰의 일부를 마스킹하고 토큰을 예측하도록 모델 학습
3. Unsupervised Contrastive Learning
- 위의 방법은 word-level tasks를 위한 encoder로 변환 가능하지만 sequence representations에는 불충분
- SimCSE를 통한 Unsupervised Contrastive Learning 적용
- GPT와 같이 transformer의 decoder-only 모델들이 이전 토큰만 봤다면, 이를 양쪽 토큰을 모두 보도록 함
- 사전학습된 방식이 bidirectional하지 않으므로 이를 적응하기 위해 다음 두 단계를 수행
- word level task를 수행하기 위해 MNTP로 BERT의 MLM을 차용
- sequence level task를 수행하기 위해 SImCSE로 sequence embedding 간의 대조학습 수행
- 실제로 이는 두 task의 실험을 통해 효과 입증
Experiments
- model: S-LLaMA-1.3B(Xia et al.,2023), LLaMA-2-7B(Touvron et al.,2023), Mistral-7B(Jiang et al.,2023a), Meta-LLaMA-3-8B(AI@Meta, 2024)
- training data
- MNTP, SimCSE: English Wikipedia
- 모든 모델의 사전학습에서 포함 되어 있었을 거라고 추정되는 데이터 선택
- 따라서 두 단계는 적응(adpatation)으로 보고, bidirectional attention과sequence representation을 구성하는 방법 외에 새로운 지식에 대한 학습은 하지 않음
- Masked Next Token Prediction
- 입력 시퀀스에서 토큰의 일부를 무작위로 마스킹
- LoRA를 사용하여 모델을 Fine-Tuning하고 이전 토큰의 Representation으로 마스크된 토큰 예측 → decoder-only LLM의 사전학습 설정과 학습 objective를 최대한 일치
- 모든 모델에 대해 단일 80GB A100 GPU에서 32의 배치 크기로 1000 steps 학습
- Unsupervised Contrastive Learning
- Unsupervised SimCSE method 적용
- MNTP LoRA weight를 기본 모델에 병합하고, 이를 이용하여 LoRA 파라미터 초기화 → 모델이 이전 단계에서 학습한 지식 유지
- MNTP → SimCSE를 학습하는 2 step
1. LLM2Vec with unsupervised learning
- setup
- MNTP training
- S-LLaMA-1.3B, LLaMA-2-7B, Meta-LLaMA-3-8B: 20%의 마스크 확률로 BERT의 마스크 전략* 적용
- Mistral-7B: 80%의 확률로 RoBERTa의 마스크 전략** 적용
- LoRA를 이용하여 RoBERTa의 MNTP training과 동일하게 수행
- SimCSE training
- 모든 모델에 대해 더 높은 dropout 확률 0.3 적용
- MNTP와 유사하게 LoRA로 학습
*BERT—입력에서 토큰의 15%를 마스크, 마스크된 토큰의 10%는 다른 토큰으로 대체되고 다른 10%는 마스크 해제
**RoBERTa—입력 토큰의 15%를 마스크하지만 마스크된 토큰에 추가적으로 후처리 하지 않음
- word-level tasks

- 기본적인 causal attention만으로도 baseline을 넘는 결과
- 추가적인 adpatation 없이 bidrectional attention만 적용하면 성능 저하
- 그러나 Mistral-7B 모델은 다른 모델과 비교하였을 때 성능 저하가 덜 함
- 모든 모델에서 MNTP를 수행하면 성능이 향상
- SimCSE를 적용하면 오히려 성능 저하 → 이는 위의 tasks가 word-level tasks라서
- sequence-level tasks

- word-level results와 유사하게, bidirectional attention은 Mistral-7B모델을 제외하고 성능에 악영향
- MNTP 학습 적용은 대부분 성능을 향상시키며, SimCSE를 적용하면 크게 성능 향상
- best causal baseline과 비교했을때, 각 모델이 49.8%, 23.2%, 37.5% 성능 향상

- LLM2Vec의 2steps(Bi, MNTP)으로도 성능 향상
- simCSE를 적용하였을때 눈에 띄게 성능이 향상
- unsupervised models에서 LLM2Vec Mistral-7B이 SOTA 달성
- Comparing to Echo embeddings
- 2 steps으로 경쟁력 있는 성능 달성
- LLM2Vec이 학습 시간 면에서 효율적
- SimCSE를 적용하면 큰 격차로 성능 향상 가능
- How does LLM2Vec affect to model?
- LLM2Vec이 모델에 직접적으로 끼치는 영향을 분석하기 위해 Echo Embedding에서 제안한 분석 수행
- LLM2Vec은 Causal Attention의 한계를 극복하고, future tokens의 정보를 Embedding에 담고자 함
- 동일한 prefix를 가지는 문장들 간의 similarity를 모델이 얼마나 잘 판단하는 지 테스트
- setup
- synthetic dataset collected by Springer at al.(2024)을 이용하여 평가
- 이는 35개 문장의 tripes $\{(q_i, s_i^+, s_i^-)\}^{35}_{i=1}$로 구성($q_i=(A_i, B_i),\ s_i^+=(A_i, C_i),\ s_i^-=(A_i,D_i)$)
- $B_i$와 $C_i$는 유사한 의미를 가지고 있으나, $B_i$와 $D_i$는 서로 상반되는 의미를 가짐
- similarity를 계산하기 위한 representations는 $A_i$을 pooling→ cosine similarity 계산
- 즉, prefix가 동일하지만 성격이 다른(positive, negative) 문장들을 prefix embedding만 비교하여 분리가 잘 되는 지 확인
- 데이터 예시

- 기대하기로는 prefix의 $A_i$의 representation에 future token의 정보가 통합되어 모델이 positive sample에 더 높은 유사성 할당

- Echo Embeddings과 비교하였을 때 같은 추이를 보임
- S-LLaMA-1.3B에서는 Bi+MNTP를 했을 때 positive와 negative examples간의 clear separation
- Mistral-7B에서는 모든 학습 설정에서 query와 positive, query와 negative examples간 유사도 큰 격차
- Why does bidirectional attention without training work for Mistral models?
- 저자들은 Mistral model에서만 유독 adpation이 없어도 bidirectional attention이 잘 동작하는 지 분석
- 학습 없이 bidirectional attention을 적용하면 실질적으로 다른 표현으로 이루어지는 것이 당연
- 이를 확인하기 위해 모든 layer에서 모든 토큰 위치의 representation을 cosine similarity 계산하여 비교

- 예상대로 LLaMA 모델에서는 학습 없이 bidirectional attention을 적용하면 성능 저하
- 거의 모든 layer와 token positions에서 낮은 cosine similarity
- 그러나 Mistral의 경우, representation이 전체적으로 높은 cosine similarity ➡ 이는 future work로
2. LLM2Vec with supervised contrastive learning
- E5 dataset 이용 contrastive learning(hard negative, in-batch negative)

- LLM2Vec을 이용한 Uni+weighted mean baseline 보다 성능 향상
- 예상대로, unsupervised SimCSE를 수행하는 건 supervised learning에서는 덜 중요하며 오히려 일부 성능 저하
- 그러나 MNTP+SimCSE가 포함된 LLM2Vec은 훨씬 더 sample-efficient
- 특히, Meta-LLaMA-3-8B+LLM2Vec(w/o simCSE)는 공개적으로 이용가능한 데이터로 학습한 모델 중 SOTA
Conclusion
- Decoder-only LLMs을 범용적인 Text Embedder로 변환하는 Unsupervised Approach, LLM2Vec제안
- word-level, sequence-level tasks에 대해 광범위한 평가 수행
- Supervised Learning, Unsupervised Learning 모두에서 LLM2Vec의 효과 입증
- Mistral-7B에 LLM2Vec을 적용하면 Unsupervised Approach Method 중 MTEB에 대한 SOTA 달성
- LLM2Vec를 Supervised Contrastive Fine-Tuning과 결합하면, Meta-LLaMA-3-8B는 공개적으로 사용 가능한 데이터(2024년5월24일기준)에서 학습하는 모델 중 SOTA
- LLM2Vec이 기본 모델에 어떤 영향을 미치는지에 대한 광범위한 분석 제공
- Mistral-7B의 흥미로운 특성으로 bidirectional attention에 대한 성능 설명
- LLM2Vec은 간단하고, 리소스 부족 등 컴퓨팅에 제약이 있는 시나리오에서 유망한 솔루션이 될 거라고 기대


