- 잘못된 내용이 있을 경우 댓글 부탁드립니다.
- 본 게시글의 목차는 논문과 상이합니다.
- 내용의 추가적인 보충 설명은 인용문 형식으로 작성되었습니다.
Prefix-Tuning Based Unsupervised Text Style Transfer
1. Abstract
- 텍스트 스타일 변환(Text Style Transfer, TST)은 생성된 텍스트의 특정 속성을 제어하는 태스크(Text Style Transfer is the task of controlling certain attributes of generated text)
- 비지도 텍스트 스타일 변환은 병렬 데이터를 사용하지 않고 내용을 보존하면서 입력 문장의 스타일을 변경할 수 있는 생성 모델을 학습하는 것을 목표
- 본 논문에서는 사전 학습된 LLM을 사용하고, 이를 위해 Prefix-Tuning based methods 제안
- 세 가지의 prefix를 구성
- shared prefix: 입력 문장의 태스크 정보
- style prefix: 대상 스타일
- content prefix: 내용 정보
- 이전 연구에서 사용된 임베딩과 비교하여 제안된 prefix는 모델에 더 풍부한 정보 제공 가능
- 또한 TST 과정에서 LM을 사용하는 재귀적(a recursive way) 방식 채택
- 입력 문장과 GPT-2간의 상호 작용을 위한 보다 효과적인 방법 제공
- 모델이 prefix를 구성하는 데 도움을 주어 성능 향상시키는 데 도움
2. Text Style Transfer
- TST는 컴퓨터 비전 및 자연어 처리에서 중요한 태스크
- 내용(content information)을 유지하면서 입력을 대상 스타일로 변환이 목표
- 병렬 데이터가 부족하므로 주로 unsupervised에 집중
- 주요 UTST(unsupervised text style transfer) 방법은 disentangled 아이디어(스타일과 내용을 분리) 기반으로 하여, 일반적으로는 RNN 또는 Transformer를 사용하여 두 개의 독립적인 임베딩으로 입력 문장의 스타일 및 내용 정보를 인코딩. 디코더는 이를 이용하여 대상 스타일을 포함하고 내용을 보존한 새로운 문장 생성
- 이전 연구에서는 인코더가 문장을 768차원의 잠재 표현(Latent representation)과 같은 고정된 크기로 인코딩을 하였으나, 이는 문장의 전체 정보를 포착하기 어렵고 작아서 정보 손실로 이어짐
- 따라서 문장을 잠재 표현으로 인코딩하지 않는 모델이 TST에 더 나은 선택일 수 있음
- 최근에는 사전 학습된 autoregressive LM이 텍스트 생성에서 큰 성공을 거둠
- GPT, LLaMA는 모두 Transformer의 디코더 부분을 모델 프레임워크로 사용
- 그러나 UTST 태스크에 대한 이들의 능력은 이전에 완전히 조사되지 않음(not been fully investigated before)
3. Main Approaches
- UTST를 위한 GPT2 기반의 새로운 Prefix-Tuning 프레임워크 제안
- UTST 분야의 이전 연구에 이어 병렬 데이터가 부족하므로 adversarial learning 프레임워크 역시 사용
- 프레임워크에는 Generator와 Discriminator 포함
- Generator에는 shared prefix, style prefix, content prefix의 세 가지 prefix 제안
- share prefix: 입력과 독립적인 태스크 특화 정보 제공
- style prefix: 대상 스타일 인코딩
- content prefix: 입력 문장의 내용 정보 추출
- 추가적인 인코더 사용하지 않음
- 단순히 사전 학습된 언어 모델을 재귀적으로 사용하여 content prefix 얻음
- Discriminator는 prefix-tuned LM을 기반으로 하여 전체 모델의 일부 파라미터만 학습
4. Contributions
- UTST를 위해 Prefix-Tuning 및 사전 학습된 LM을 기반으로 새로운 방법 제안
- 이전 방법보다 표현력이 뛰어나고 파라미터의 2%만 학습
- 생성을 위해 동일한 LM에 제공될 content prefix를 content information을 추출하기 위해 LM을 반복적으로 사용하는 전략 제안
- 이는 학습 가능한 파라미터와 고정된 파라미터 간의 상호 작용을 위한 효과적인 방법 제공
- 잘 알려진 데이터셋을 대상으로 수행된 실행에서 제안 방법인 SOTA baseline보다 성능이 우수
- human and ablation studies 평가 추가
5. Relate Works
6. The Proposed Method
6.1. Architecture
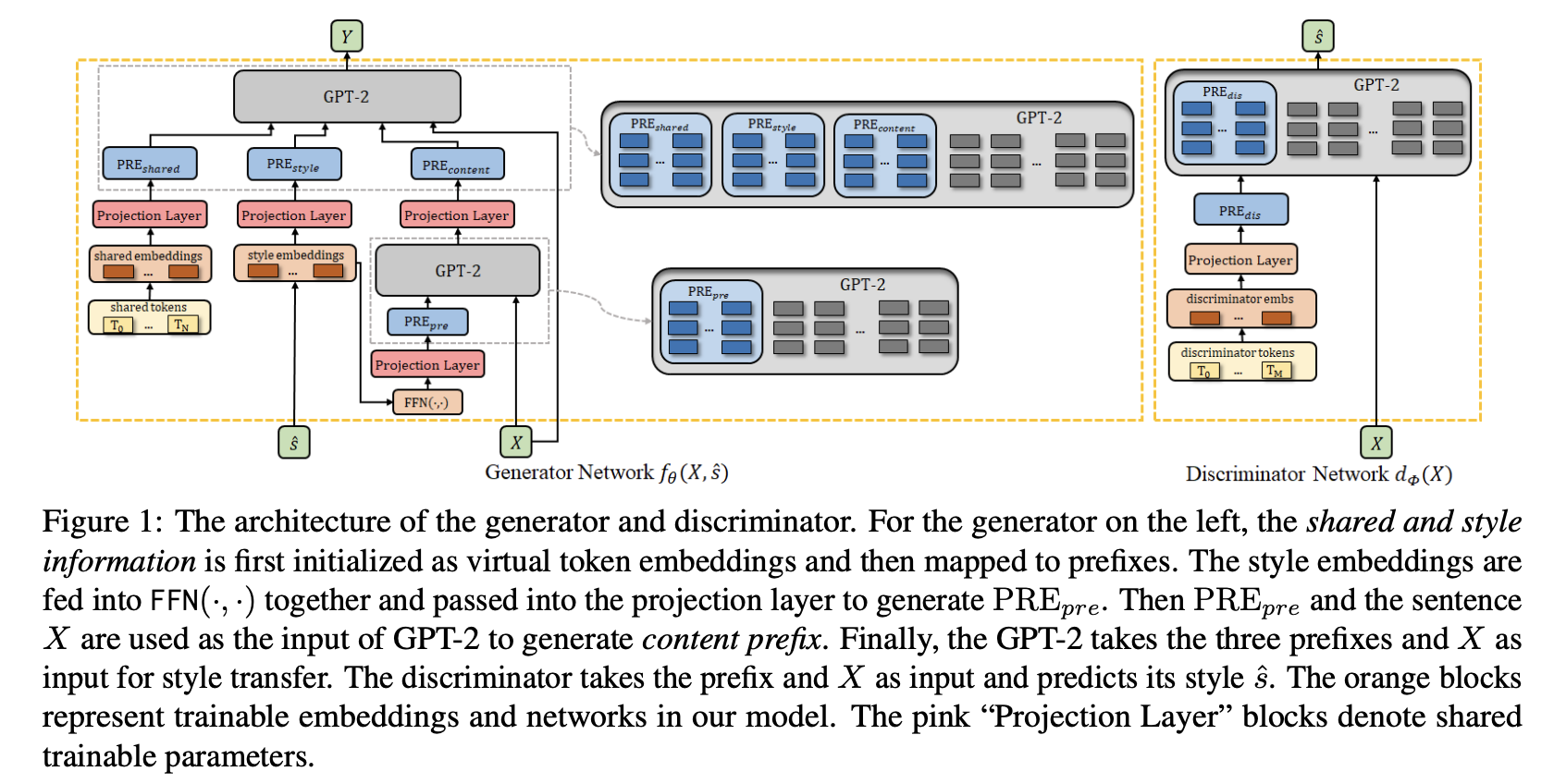
6.2. Problem Formalization

- TST의 목표는 스타일을 변환하면서 그 내용은 유지하는 것
- 구체적으로 스타일 $s$와 입력 문장 $X$는 모델 $f_theta(X, \hat{s})$으로 목표 스타일인 \hat{s}인 새로운 문장 $Y$로 변환
- unsupervised는 $(X, Y)$가 없으므로 목표는 Unpaired training data $D$로부터 모델 $f$를 얻는 것
6.3. Model overview
- GPT2를 backbone으로 사용, Decoder 기반 모델 GPT2를 선택하여 style과 input text를 prefixes로 encode
- 다른 UTST 모델과 마찬가지로 모델도 adversarial learning 프레임워크 적용

- 전체 모델 구조는 Generator Network와 Discriminator Network로 구성
- Generator는 입력 문장 $X$와 출력 대상 스타일 $\hat{s}$을 사용하여 출력 문장 $Y$ 생성
- Discriminator는 입력 문장의 스타일을 예측
- embedding table을 사용하여 스타일 토큰인 단일 벡터 $s$를 임베딩으로 변환
- LM의 style prefix를 얻기 위해 스타일 임베딩은 projection layer를 이용하여 $L$ 벡터($L$ vectors)로 preojected
- 파라미터 수를 줄이고 학습 가능한 파라미터와 고정된 파라미터 간의 상호작용(interaction)이 가능하도록 style prefix와 입력 문장은 content prefix를 생성하도록 동일한 사전학습 LM으로 제공

- Discriminator에서는 $M$개의 discriminator 토큰이 판별하는 데 필요한 정보를 제공하도록 설계
- prefix 생성 절차는 generator의 shared prefix와 유사
6.3. Prefix-Tuning Based Generator Network
- prefix는 입력 문장의 토큰들을 제외하고 사전 학습된 LM의 certain layer를 위한 입력
- 이는 prefix tokens이 l번째 layer의 일반 문장 토큰들이 l-1번 째 layer에서 온 것과 다르게 모든 layer의 prefix tokens이 projection layer로부터 왔다는 의미
6.3.1. Shared Prefix
- Shared prefix의 역할은 사전 학습 LM에 태스크 관련 정보를 제공
- 다양한 데이터셋에서 특정한 TST 수행 시, shared prefixes는 사전 학습 LM으로 필요한 다양한 정보를 캡쳐할 수 있을 거라고 예상
- shared prefix는 shared tokens($T_0, ..., T_N$)에서 생성
- 이는 일반적인 토큰과 유사하게, 먼저 $N$ shared embeddings으로 변환되며, 이는 feed-forward NN에서 $PRE_{shared}$로 표시되는 $N$ shared prefixes로 projected
- 각 shared prefix는 $L$개의 벡터 집합으로, $L$은 사전 학습 LM의 layer 수

6.3.2. Style Prefix
- 이전 연구에서는 대상 스타일이 특수 토큰으로 입력 문장에 연결이 되거나, 잠재 표현으로 변환되어 디코더에 공급됨
- 이들과 달리 본 논문에서는 대상 스타일을 prefix로 변환한 다음 제안 방법의 generator에 입력으로 제공
- 따라서 style prefixes를 생성하는 구성 요소에는 학습 가능한 파라미터가 더 많이 포함 → 표현력 상승
- 따라서 prefix를 사용하는 것이 스타일의 정보를 제공하는데 임베딩 보다 낫고, 스타일 변환에 더 유리

- prefix의 효과는 모든 transformer activation layers에 전파(propagated upward)되고 오른쪽으로는 입력 토큰으로 전파
- shared prefix를 구성하는 것과 유사하게 projection layer를 사용하여 style embedding(target style로부터 embedding table을 이용하여 만들어진)을 style prefix $PRE_{style}$에 매핑
6.3.3. Content Prefix and Recursively Applying LM
- content prefix의 역할은 생성 과정에서 보존되어야 하는 내용을 강조하는 것
- 사전 학습 LM에 원래 문장이 입력되더라도 제안한 content prefix를 적용하면 성능을 높일 수 있음을 확인
- 동일한 사전학습 LM을 이용하여 $PRE_{pre}$와 입력 문장을 이용하여 $PRE_{content}$를 생성함
- $PRE_{content}$는 스타일 정보를 표현
- 모든 스타일의 임베딩은 연결되어 FFNN을 통해 차원을 줄이고, Projection layer를 거쳐 $PRE_{content}$를 생성
최종적으로, 이렇게 만들어진 세 개의 prefix는 다같이 $Y$를 생성하기 위해 GPT2 모델의 prefix로 사용됨
6.3.4. Generator Losses
- Generator에는 self-reconstruction loss, style transfer loss, cycle generation loss가 사용
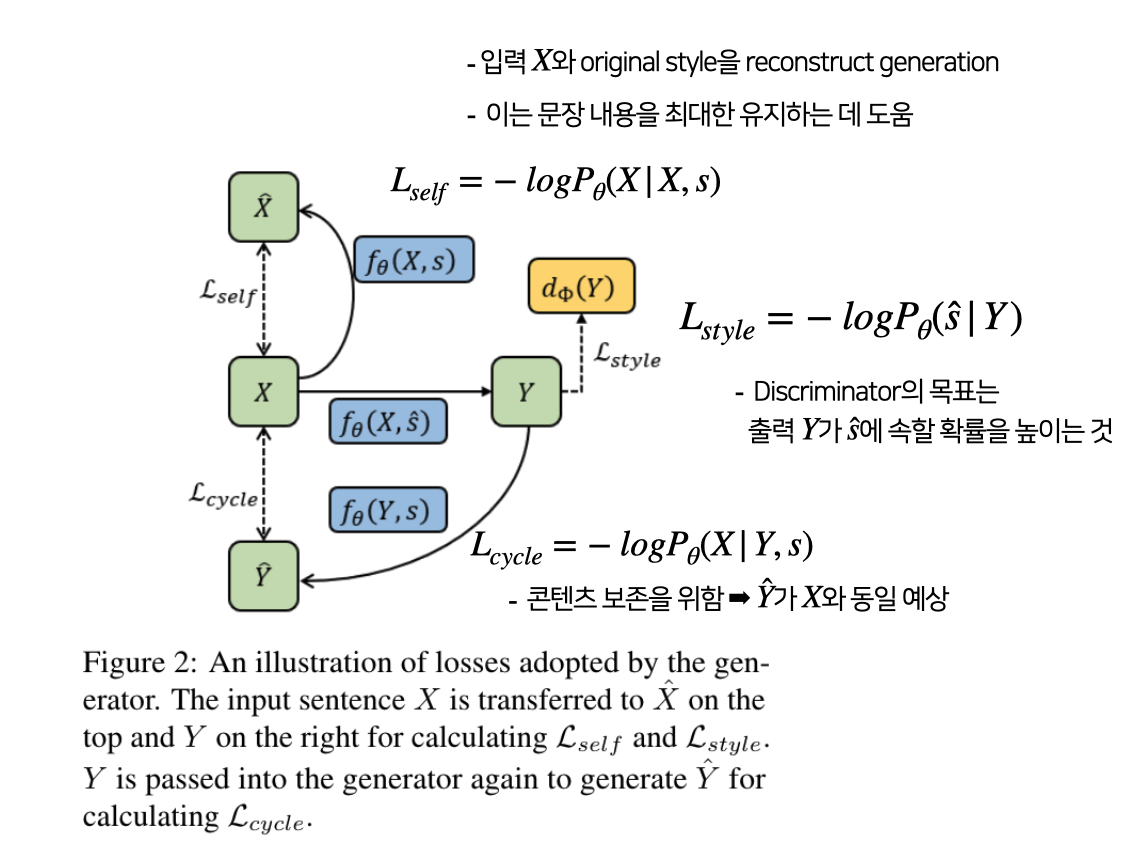
- $L_{gen} = \lambda_1L_{self} + \lambda_2L_{cycle} + \lambda_3L_{style}$
- $L_{gen}$로 Generator의 파라미터를 업데이트 *Discriminator는 해당 loss로 업데이트하지 않음.
- $\theta$는 Prefix를 구성하는 데 사용되는 파라미터만 포함
6.4. Discriminator Network
6.4.1. Discriminator
- 입력 문장의 스타일을 분류
- 2가지의 스타일이 존재하는 데이터셋의 경우, 3가지 class로 분류($style_1, style_2, s_{fake}$)
- $s_{fake}$: (generated) sentence
- 모델의 마지막 hidden layer의 평균값을 linear layer에 전달하여 문장 분류 확률 계산
- Generator와 Discriminator의 일관성을 위해 마찬가지로 prefix-based GPT-2 구조로 학습
6.4.2. Discriminator Loss
- 학습 중 문장 $X$는 train corpus나 Generator에 의해 제공
- $X$가 corpus에서 제공되는 경우 $s_target$은 문장의 style,
- Generator에 의해 제공되는 경우 target은 $s_{fake}$
- $L_{dis} = -logP_ϕ(s_{target}|X)$
7. Experiments
7.1. Dataset
- 실험에 사용된 데이터는 "Yelp", "IMDb"
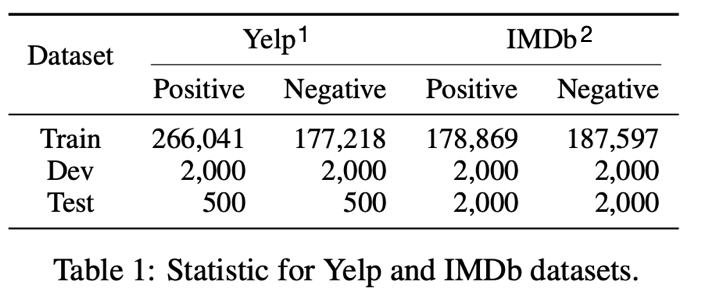
- Yelp Reviews Dataset: 식당, 영업장 리뷰
- IMDb Movie Review Dataset: 영화 리뷰
- disentanglement와 prompt-based 방법을 사용한 Deep Latent(He et al., 2020), Style Transformer(Dai et al., 2019), RACoLN(Lee et al., 2021), LaMDA(Reif et al., 2022)과 비교
7.2. Automatic Evaluation
- Measure of Style
- 생성된 문장의 스타일을 예측하기 위해 classifier의 accuracy를 평가
- fastText(Joulin et al., 2016)를 사용하여 데이터셋에 대해 classifier 학습
- accuracy가 높을수록 더 많은 출력 문장이 target과 동일한 스타일을 가짐을 확인 가능
- Measure of Content
- 생성된 문장과 원본 입력 문장 사이의 BLEUScore를 계산하여 내용 보존성 측정
- BLEUScore가 높을수록 원본 문장의 단어를 더 많이 포함하고 있음을 의미
- Measure of fluency
- Perplexity(PPL) 사용 ➡ PPL이 낮은 모델이 더 유창한 문장을 생성할 수 있음
- 이를 위해 두 데이터셋에 대하여 3-gram 언어 모델을 KenLM(Heafield, 2011)을 사용하여 학습
7.3. Human Evaluation
- 보다 정확한 결과를 평가하기 위해 사람에 의한 평가 수행
- 각 데이터셋에 대하여 테스트셋에서 200개의 문장을 무작위로 선택
- 4명의 annotators에게 “원본 문장”, “target 스타일”, “출력 문장”(제안 모델과 비교 모델)
- Scores는 1점(매우 낮음)부터 5점(매우 높음)까지의 범위를 가짐
- 평균 점수를 최종 점수로 사용
7.4. Automatic Evaluation
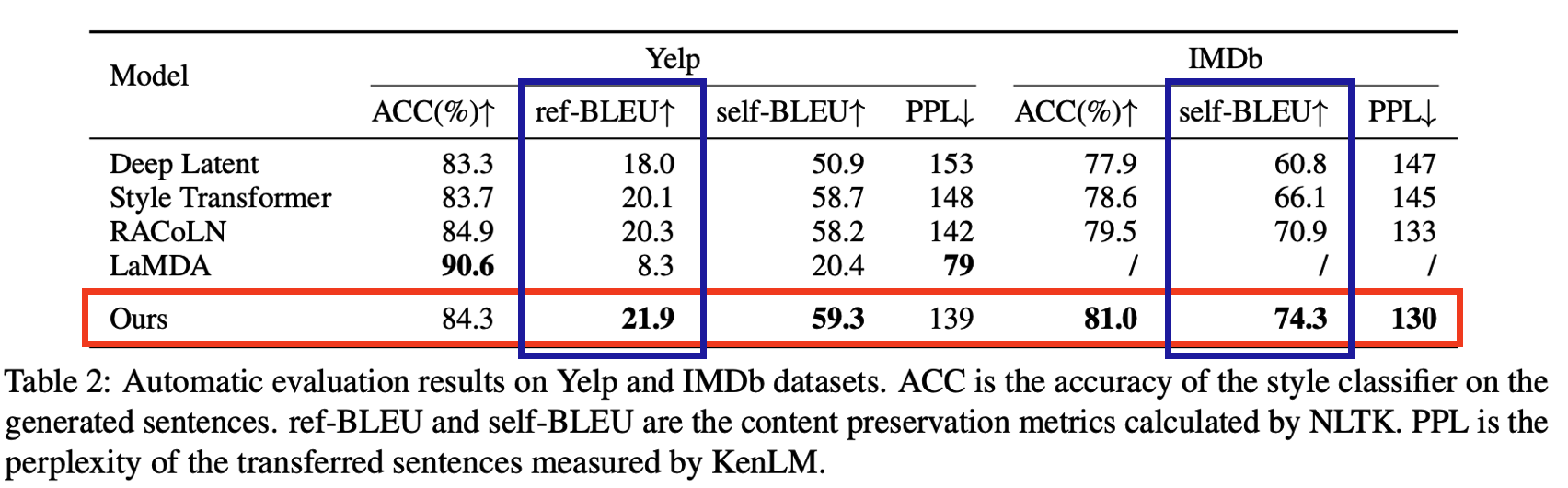
- ACC에서 Yelp는 경쟁력 있는 성능 달성 그리고 IMDb에서는 비교 모델들 보다 높은 성능
- 평균 문장의 길이가 긴 IMDb 데이터셋의 style control이 다른 모델들 보다 우수한 성능
➡ 더 많은 정보를 포함하는 prefix-tuning으로 style을 인코딩하므로 긴 텍스트에 더 잘 대처 가능
➡ 제안 모델의 Discriminator는 RNN 보다 텍스트를 더 잘 처리할 수 있는 GPT-2를 사용 - GPT-2 반복적 사용 ➡ 입력 문장과 LM 간의 충분한 상호작용으로 내용 보존성 확보
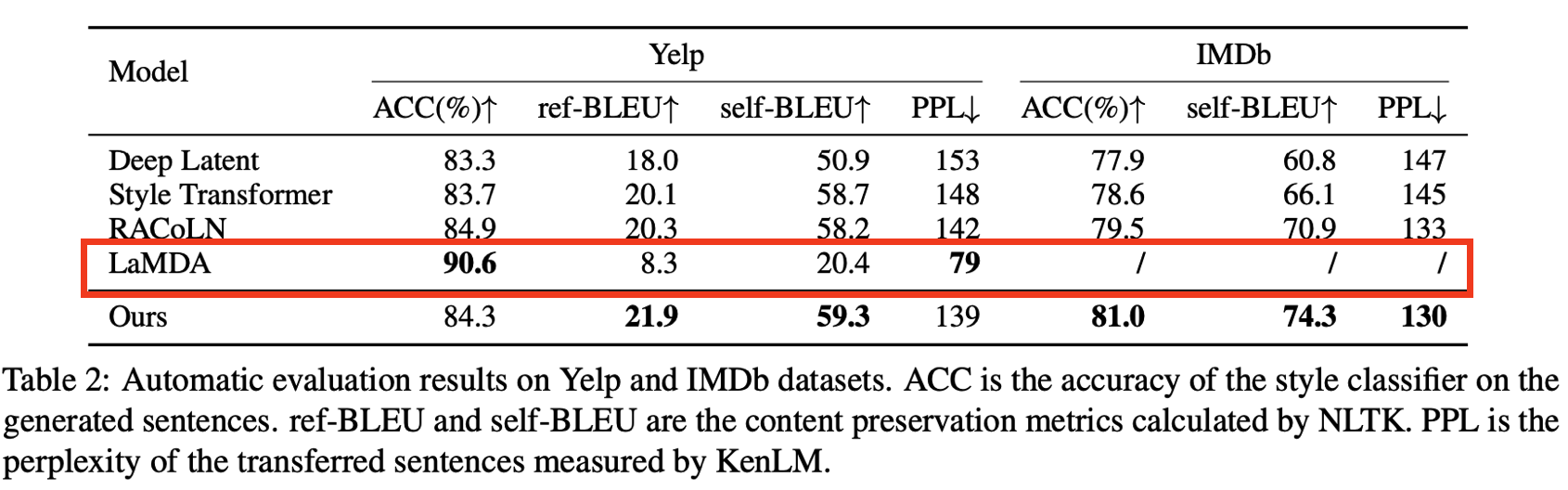
- LaMDA(Reif et al., 2022)는 LLM을 기반으로 하는 Zero-shot 방식
- 상당히 높은 ACC 결과 확인 가능
- LLM을 사용하면 보다 유창한 문장을 출력하여 PPL 지표 개선에 도움
- 그러나 이런 방법은 낮은 제어 가능성으로 내용 보존 성능 저하
7.5. Human Evaluation
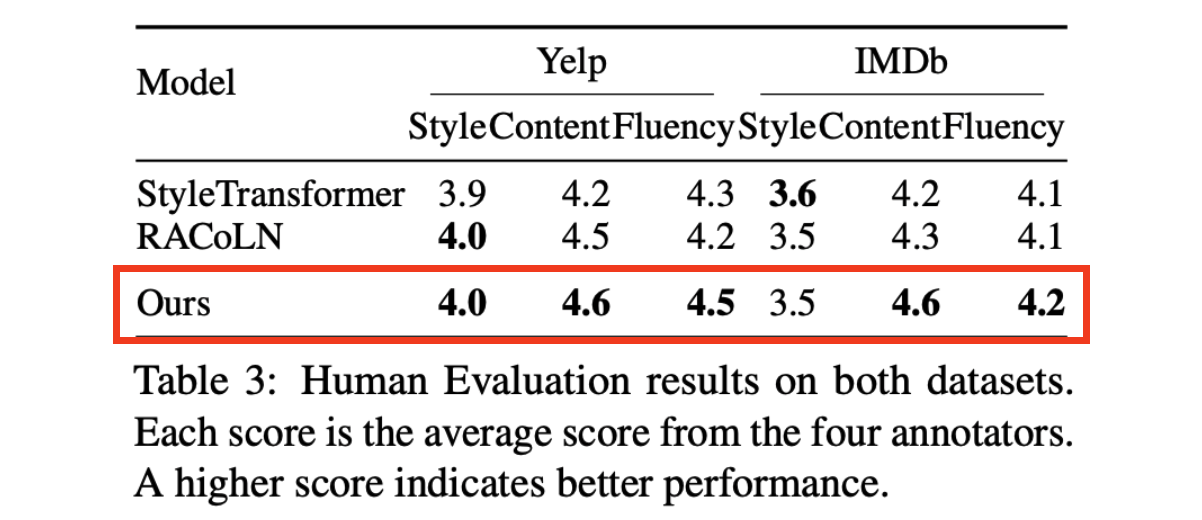
- 기본적으로 정량 평가와 일치하는 결과
- 내용 보존성과 유창성 측면에서 다른 두 비교 모델 보다 높은 성능
- 스타일 측면에서는 다른 모델과 비슷한 성능으로 유지
➡ 제안 방법이 원문의 내용 보존성, 유창성 그리고 스타일 전달 측면에서의 효과 확인 가능
7.6. Ablation Study
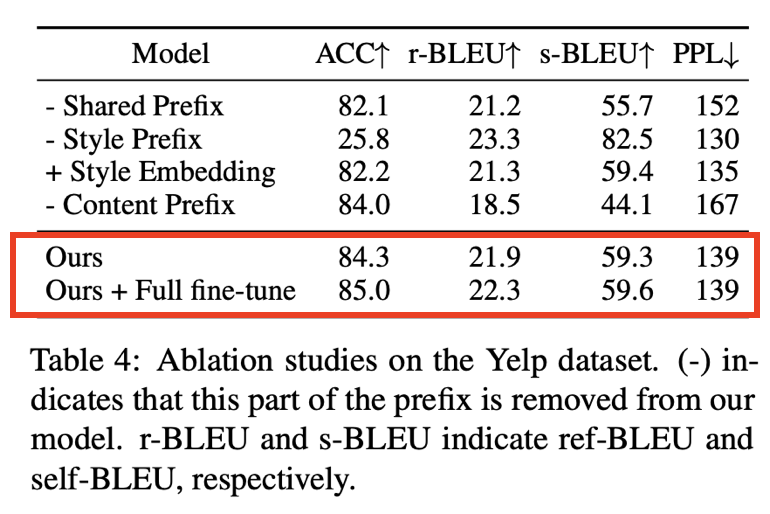
- 각 모듈이 성능에 미치는 영향을 파악하기 위해 Ablation Studies 수행(on Yelp dataset)
- 각 prefix(shared prefix, style prefix, content prefix)를 차례로 제거
- Style Embedding: Style Encoding 방법에 따른 성능 비교 위함
- Ours + Full fine-tune: Prefix-Tuning과 비교하기 위함
- Share Prefix
- 스타일 제어 및 내용 보존성 하락
- 태스크 프롬프트이므로 태스크 정보 일부 손실 의미
- Style Prefix: 스타일 제어 하락
- 스타일 정보가 없으면 모델은 스타일을 수정하지 않고, 입력 문장을 그대로 복사하는 모델로 쉽게 변질
- 전체 모델보다 BLEU는 높지만 ACC 점수 크게 하락
- Style Embedding
- ACC metric에서 Style Prefix 보다 낮음
- Style Prefix가 더 많은 스타일 정보를 제공하고, 모델 성능 개선 여지가 있음을 확인 가능
- Fine-Tuning
- 전체 모델을 Fine-Tuning하는 건 성능의 상한성
- 2%의 파라미터만 학습하면 되므로 Prefix-Tuning은 성능을 비교하였을 때 경쟁력 있음
7.7. Case Study

- Yelp dataset에서 몇 개의 문장을 샘플링하여 비교
- 비교 모델의 문장은 일관성이 없거나 일부 문법 오류 발생
- 제안 모델에서는 나타나지 않음
8. Conclusion and Limitations
- PLM을 활용하는 Prefix-Tuning 기반의 Unsupervised Text Style Transfer 제안
- Prefix-Tuning을 사용하여 Target Style과 입력 텍스트를 모두 인코딩
- 내용 추출과 Style Transfer 과정에서 GPT-2를 반복적으로 사용하는 방법 설계
➡ 입력 문장과 LM이 상호작용을 하여 LM의 Style Transfer 성능 최대 활용
- 실험 결과, 제안 방법은 내용 보존성과 유창성 측면에서 높은 성능 달성
- 제안 방법은 새로운 Style Transfer Tasks에서 재학습 필요
- 따라서 향후 상황에 맞는 학습 개념을 결합하고 ChatGPT와 같은 강력한 PLM으로 zero-shot 연구


