- 논문 제목: Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
- 학회/저널: Advances in Neural Information Processing Systems: NIPS 2023
- like: paper, github

Introduction
- 프롬프팅(Prompting)은 2020년, GPT3 논문에서 그 효과를 입증
- 모델의 사전 학습 지식 만으로 Fine-Tuning을 하지 않더라도 입력으로 지침과 예시만 제공해도 어느 정도 성능 보장
(Zero-shot, one-shot, few-shot) 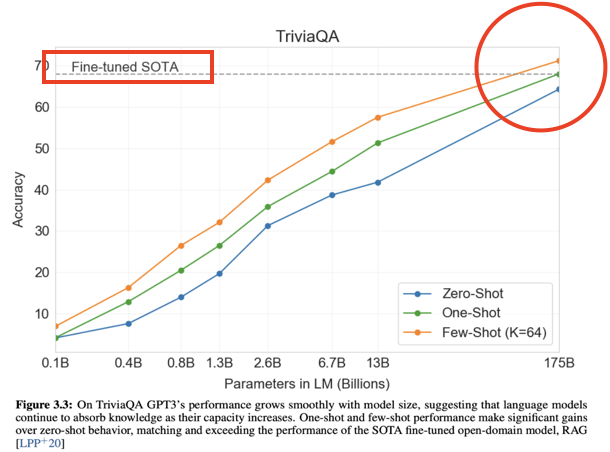
- 모델의 사전 학습 지식 만으로 Fine-Tuning을 하지 않더라도 입력으로 지침과 예시만 제공해도 어느 정도 성능 보장
- 그러나 프롬프팅을 위해 프롬프트를 작성하는 어려움 존재 > 프롬프트 엔지니어링(prompt engineering) 기술 대두
- 흔히들 말하는 프롬프트 엔지니어링 기술은 두 가지 기술로 나뉨 - Hard Prompt, Soft Prompt
하드 프롬프트(hard prompt) vs. 소프트 프롬프트(soft prompt)
- 하드 프롬프트
- 해석 가능한 토큰(자연어)의 Hand-Crafted Sequences로, 사람이 직접 작성
- 적합한 하드 프롬프트를 작성하는 건 전문적인 영역으로 많은 시행 착오와 직관에 의해 발견
- 소프트 프롬프트
- Continuous-Valued Language Embeddings으로 구성
- 사람이 보고 자연어처럼 직접적으로 해석 불가능
- Mathematical Science으로 발견
- Gradient-based Optmizers, Language Curated Datasets
- 주로 LM의 파라미터는 고정(freeze)을 하고, prompt를 구성하는 tensor만 LM의 역전파로 업데이트
- 대규모 데이터셋을 이용하여 특정 태스크에 대해 높은 성능을 보이는 프롬프트를 생성하는 목적
- Continuous-Valued Language Embeddings으로 구성
Soft Prompt
- 특히 소프트 프롬프트 같은 경우, 하드 프롬프트의 단점 극복 및 PEFT 장점을 가짐
PEFT: Parameter-Efficient Fine-Tuning:
모델의 모든 파라미터를 Fine-Tuning 하지 않고 효율적으로 다운스트림 태스크에 대하여 대규모 사전학습 모델을 학습할 수 있는 Fine-Tuning(LoRA, QLoRA, Prefix-Tuning 등)
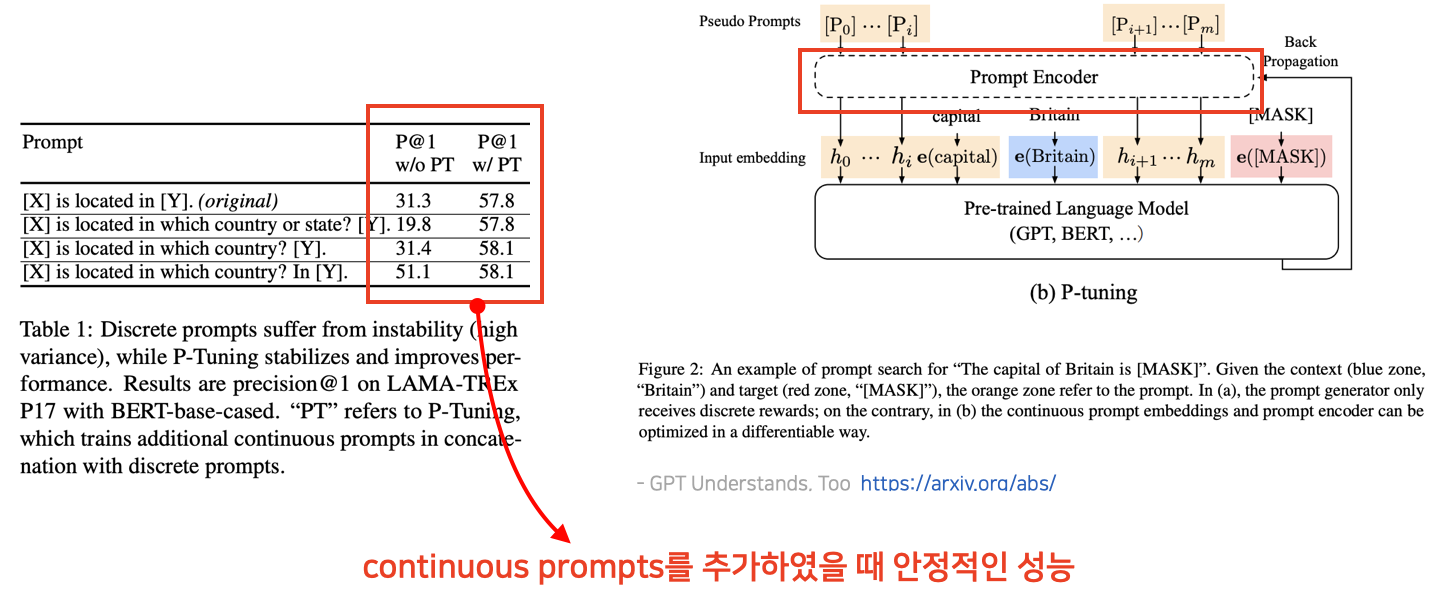
- Table1처럼 하드 프롬프트의 경우, 프롬프트를 구성하는 자연어 단어가 일부라도 달라지는 경우 성능 차이가 큼
- 소프트 프롬프트에는 대표적으로 Prefix-Tuning과 P-Tuning
- Prefix-Tuning
- 트랜스포머 기반의 모델에서 사용
- 모든 레이어에서 입력 문장 앞(prefix)에 일련의 태스크 특화 벡터를 추가하여 이를 학습
- 벡터만 학습하는 경우 성능이 불안정하여 MLP로 reparameterization
- 실제 구현에서는 Past Key-Value 사용
- P-Tuning
- LSTM인 Prompt Encoder를 두어 LSTM만 학습
- 입력 문장 사이사이에 프롬프트를 위치시켜 학습
- 실제 단어나 토큰 대신 continuous한 실수 값으로 구성된 embedding을 사용
→ 프롬프트의 임베딩 시퀀스가 실제 언어적인 의미나 토큰 시퀀스로 직관적으로 이해되거나 해석되기 어려움
(limited semantic scrutability)
Hard Prompt Advantages
- 본 논문에서 제안하는 방법은 각 프롬프트 기술이 가지고 있는 장점을 취하여 혼합
- 두 프롬프트를 비교하였을 때, 하드 프롬프트는 다음과 같은 장점을 가짐
| Hard prompt | Soft Prompt |
|---|---|
| 다양한 태스크를 수행하기 위해 여러 프롬프트 조합하여 사용 가능 | 한 태스크에 대하여 고도로 전문화 |
| 목적에 따라 직접 수정 가능 및 portable한 특성 | 모델 간 임베딩 차원, representation space 차이로 portable하지 않음 |
| API로만 접근 가능한 모델과, 입력의 임베딩을 제어 불가능할 때 사용 가능 | 입력 임베딩 수정 및 모델 구조 수정 필요 |
*portable: 다른 모델에서도 해당 프롬프트를 사용 가능
- 소프트 프롬프트의 경우, LM과 같이 학습을 하는 것이므로 해당 다운스트림 태스크에 특화되어 있음
- 이는 기존 제안된 소프트 프롬프트 목적과도 부합함
- LM을 Fine-Tuning하지 않아도 태스크별 소프트 프롬프트를 저장하여 사용
→ Hard Vocabulary Constraints + Continuous Soft-Prompt Optimization
→ Task-Sepecific하고 해석 가능한 토큰을 생성하는 방법 제안
- 즉, 모델의 vocab 내에서만 token이 등장하도록 하되(해석 가능), 최적화를 위해 소프트 프롬프트를 사용
Related Work
1. Hard Prompt Optimization
- 저자는 두 가지 논문에서 영감을 얻음
- AutoPrompt(2020), FluentPrompt(2022)
- AutoPrompt(2020)는 트랜스포머 기반 Discrete Prompt Optimization Framework
- HotFlip을 활용하며, gradient를 이용하여 프롬프트 각 위치에 대한 최적의 token을 greedily하게 탐색
HotFlip
- 개별 문자, 단어 또는 구문을 식별하고 입력 텍스트를 수정하여 모델의 예측 변화를 극대화하기 위해 도입
- 모델의 손실 함수의 기울이를 사용하여 입력의 어느 부분이 예측에 가장 크게 기여하는지 확인
- FluentPrompt(2022)는 Langevin dynamics를 활용하여 프롬프트 임베딩을 최적화, fluency penelty 추가
- 이 두 가지 gradient-based method를 baseline으로 봄
AutoPrompt(2022)
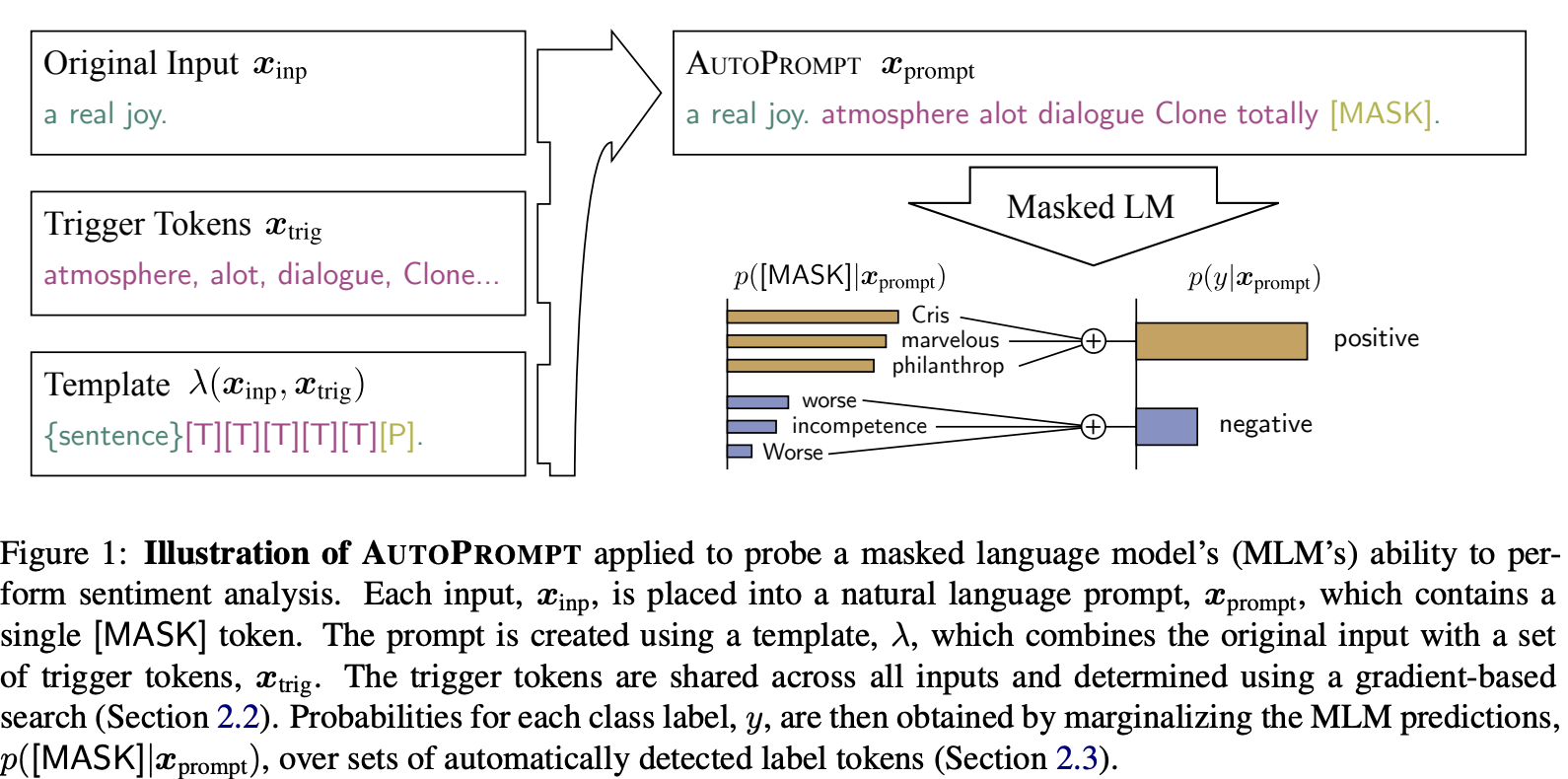
- Prompt($x_{prompt}$) = {입력 문장}+{트리거 토큰}+[MASK]
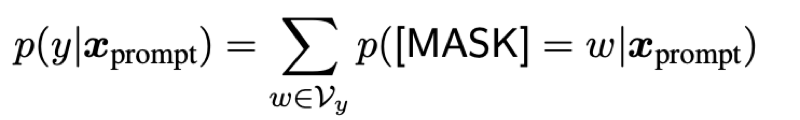
- 클래스 레이블 $y$에 대한 확률은 해당 프롬프트를 넣었을 때, 가능성이 있는 레이블에 대한 모든 확률의 합(marginalizing)
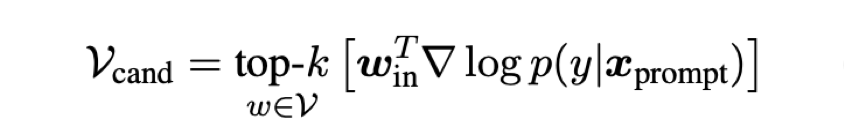
- Gradient-based Prompt Search
- 레이블의 likelihood를 최대화 하는 트리거 토큰 검색
- prompt에 대한 $logp(y|x_{prompt})$의 gradient 계산
- word embedding $w$와 내적(예측하는 데 가장 영향을 많이 주는 word 선택)
- score가 가장 높은 $k$개를 candidates로 선정
- 그러나 gradient step 마다, 프롬프트의 각 위치에서 후보를 평가해야 하며 추가적 forward passes 필요
- $k$만큼 비용이 빠르게 증가하는 단점 존재
→ 이를 제안 방법에서는 $k$를 1로 설정하고, 배치 단위로 gradient를 합산, 각 후보를 평가하는 과정 없음
2. Prompt Discovery from Images
- 이미지로부터 풍부한 정보를 추출하고 이를 자연어로 옮기는 과정을 image captioning이라고 함
- 이미지-텍스트 쌍에 대한 Large Captioning Models을 학습하여 목표 달성
- 그러나 이러한 captions은 종종 일반적이어서, 새롭거나 보이지 않는 객체를 정확히 반영하지 못함
- 이전 연구에서는 소프트 프롬프트를 사용하여 text-guided diffusion model을 optimize하는 방법을 제안하여 원본 이미지의 개념과 유사한 시각적 개념을 생성할 수 있도록 함
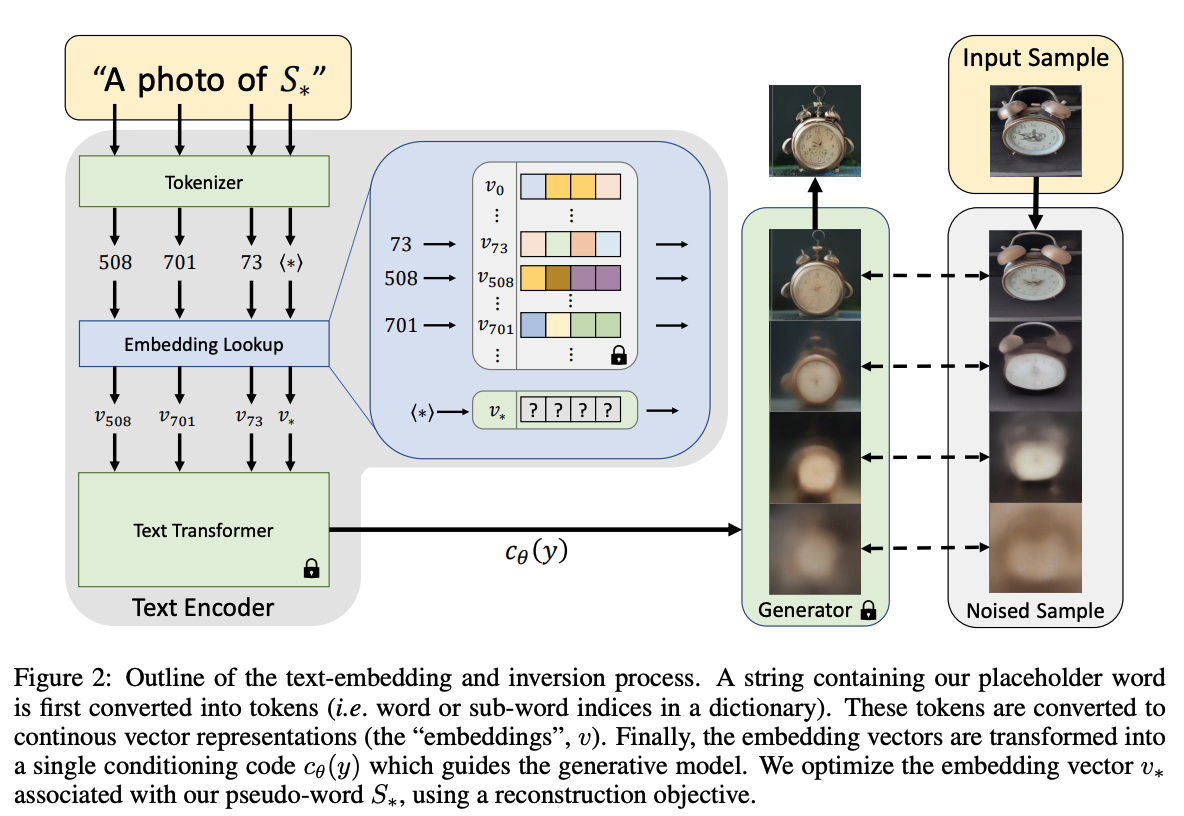
- 이 논문은 LDM(Latent Diffusion Model)을 학습하지 않고, 프롬프트를 학습하는 방법 제안
- 입력 문자열의 각 단어 또는 하위 단어는 토큰으로 변환, 이는 고유한 임베딩 벡터로 연결(파란색 박스)
- 학습하고자 하는 새로운 개념을 나타내는 문자열 $$S_*$$ 지정
- 임베딩 프로세스에 개입하여 토큰화된 문자열과 연관된 벡터를 새로운 학습된 임베딩 $$v_*$$으로 대체
- 주어진 이미지(3-5장)에 대하여 LDM의 Objective function을 최소화 하는 방향으로 $$v_*$$를 학습
→ 이 경우 최종 소프트 프롬프트가 효과적이기는 하나, diffusion model을 통한 optimize는 비용이 많이 들고 이러한 프롬프트를 해석하거나 다른 모델에서는 사용 불가능
정리
- 하드 프롬프트는 설계해야 하는 어려움이 있고, 이전 연구에서는 하드 프롬프트를 최적화하기 위해서 각 토큰에 대한 후보를 평가해야 하므로 추가적인 forward passes가 필요한 오버헤드가 존재
- 그러나 하드 프롬프트는 사람이 보기에 직관적이고 해석 가능하다는 장점이 있음
- 또한 모델의 구조와 상관없이 프롬프트를 생성하고 적용할 수 있음
- 소프트 프롬프트는 하드 프롬프트의 단점을 극복할 수 있으나, 다른 모델에는 사용 불가능
- 따라서 저자는 하드 프롬프트의 해석 가능성과 용이성 그리고 소프트 프롬프트의 유연성을 결합한 방법 제안
Method
PEZ Algorithm

- 각 forward pass 동안 gradient를 계산하기 전에 현재 임베딩 $$\mathbf{P}$$에서 가장 가까운 이웃 $$\mathbf{P}'$$에 projection
def nn_project(curr_embeds, embedding_layer):
seq_len,emb_dim = curr_embeds.shape
# Using the sentence transformers semantic search which is
# a dot product exact kNN search between a set of
# query vectors and a corpus of vectors
curr_embeds = curr_embeds.reshape((-1,emb_dim))
curr_embeds = normalize_embeddings(curr_embeds) # queries
embedding_matrix = embedding_layer.weight
embedding_matrix = normalize_embeddings(embedding_matrix) # corpus
hits = semantic_search(curr_embeds, embedding_matrix,
query_chunk_size=curr_embeds.shape[0],
top_k=3,
score_function=dot_score)
nn_indices = torch.tensor([hit[0]["corpus_id"] for hit in hits], device=device)
projected_embeds = embedding_layer(nn_indices)
return projected_embeds, nn_indices- 그리고 discrete vectors의 gradient를 이용하여 continuous/soft $$\mathbf{P}$$를 업데이트
- 즉, 소프트 프롬프트를 업데이트하되 이를 업데이트 하기 위한 gradient 값은 discrete 레벨에서 구하겠다는 의미
- 최종적으로 소프트 프롬프트는 Projection function으로 하드 프롬프트로 변환
Prompt Inversion with CLIP
- 대부분 text-guided Diffusion Model은 CLIP Text-Encoder와 사전학습된 Text-Decoder 사용
- 이미지를 설명하는 캡션을 최적화하고, 이 캡션을 Diffusion Model의 프롬프트로 사용
- CLIP 모델에는 자체 Image Encoder가 있으므로 이를 활용하여 PEZ method 적용 가능
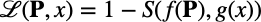
- 만들어진 하드 프롬프트 임베딩과 대상 이미지 임베딩의 유사도를 계산
- 이렇게 하므로 전체 Diffusion Model에 대한 Gradient 계산을 피할 수 있음
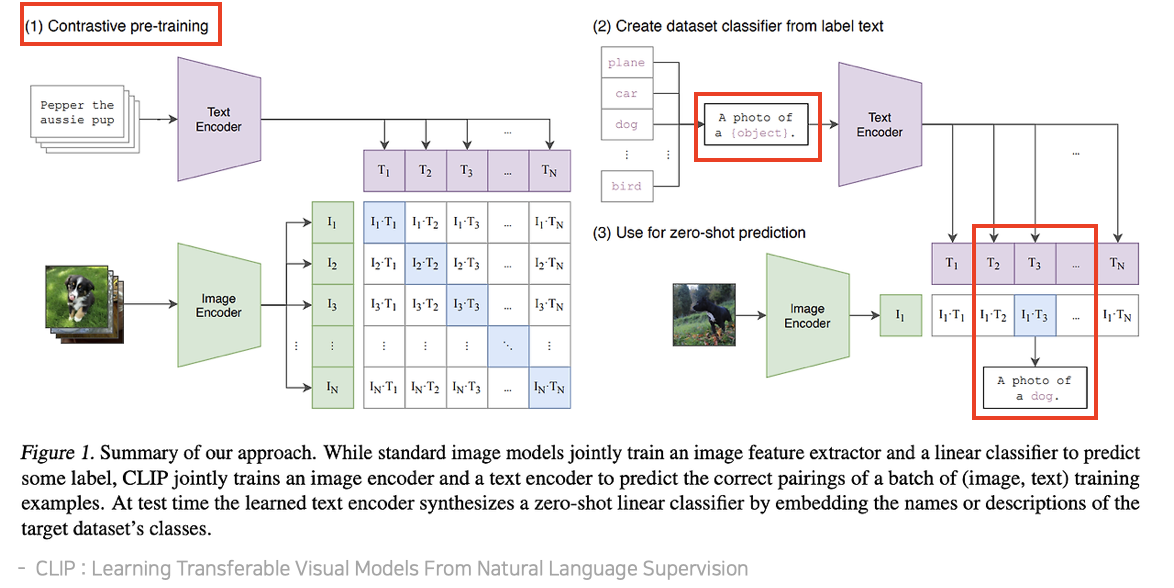
- CLIP은 N개의 이미지-텍스트 쌍의 배치가 주어졌을 때, $$NxN$$개의 가능한 쌍을 예측하도록 학습
- 이를 위해 CLIP은 각 쌍의 코사인 유사도를 최대화 하면서, $$N^2-N$$개의 negative pair에 대한 값은 최소화 하도록 하는 contrastive learning으로 학습(왼쪽 이미지)
Experiments
- Style Transfer를 위한 하드 프롬프트 학습
- 동일한 스타일을 가진 샘플이 여러 개 주어지면 하드 프롬프트가 스타일을 추출하여 다른 객체나 장면으로 전환 가능
- 주어진 프롬프트 템플릿:




