- 논문: https://arxiv.org/pdf/1804.06437
- 소스코드: https://github.com/lijuncen/Sentiment-and-Style-Transfer
- 2018년도에 나온 RNN을 사용한 꽤나 오래된 논문
- 요즘 관심을 가지는 검색과 결합한 스타일 변환 논문이라서 읽어봄

Abstract
- 텍스트 스타일 변환은 문장의 특정 속성(e.g., 감정)을 바꾸는 동시에 속성과 무관한 내용은 유지하는 작업
- 저자는 이전 연구에서 사용된 적대적 학습이 고품질 결과 생성에 어려움이 있음을 지적
- 텍스트 속성이 종종 독특한 구절로 표시된다는 관찰에 기반하여 더 간단한 방법 제안
- 효과적인 방법으로 원래 문장의 속성과 관련된 구절 삭제 → 목표 속성 관련 구절 검색 → RNN으로 결합 → 생성
- 실험 결과, 이 방법은 세 가지의 데이터셋(yelp, amazon, image caption)에서 문법적이고 적절한 응답 생성
method

0. Problem Statement
- $D = \{(x_1, v_1), ..., (x_m, v_m)\}$: a corpus of labeled sentences
- $x_i$: a sentence
- $v_i \in V$: the set of possible attributes(e.g., for sentiment, $V=\{\text{"positive"}, \text{"negative}\}$)
- $D_v = \{x:(x, v) \in D \}$: the set of sentences in the corpus with attribute $v$
- $a(x, v^{src})$: a set of attribute markers
- $c(x, v^{src})$: a sequence of content words
- 모델이 학습하고자 하는 목표는 input으로 $(x, v^{tgt})$을 받으면 output으로 content인 $x$와 $v^{tgt}를 가지는 $$y$ 출력

1. Delete
- 목표: 입력 문장에서 스타일을 나타내는 단어 또는 구문(attribute markers)을 식별 → 삭제 → content만 남김
- extracting attribute markers
- 각 attribute 값(positive, negative)을 가진 문장에서 특정 n-gram이 나타나는 빈도(salience) 계산
- 특정 임계값보다 높은 salience를 가진 n-gram을 해당 attribute의 makers로 사용
- 다른 스타일을 가진 문장 집합에서 나타날 횟수 대비 현재 스타일에서 나타나는 횟수로 계산
- $\lambda$는 n-gram이 나타나지 않는 경우를 고려한 smoothing parameter(논문에서는 1로 사용)

- delete: 입력 문장에서 추출한 attribute marker를 삭제 → 남은 단어들은 보존되어야 하는 내용, content로 간주
2. Retrieve
- 목표: 목표 스타일을 가지면서 스타일이 삭제된 콘텐츠와 유사한 콘텐츠를 가진 문장을 corpus에서 검색
- 방법
- 유사도 측정: 1단계에서 얻은 content와 목표 스타일의 content 간 유사도 측정(tf-idf 기반 단어 중복 or 유클리드 거리)
- 검색: 가장 유사한 문장을 목표 스타일 문장으로 선택
- $x^{tgt} = argmin_{x' \in D_{v^{tgt}}} d(c(x, v^{src}), c(x', v^{tgt}))$
- $d$: distancem metric comparing two sequences of words
3. Generate
- 학습 목표: 자연스러운 목표 스타일 문장 생성
- 목표: content, 목표 스타일 그리고 검색된 목표 스타일의 content를 활용하여 자연스럽고 문법적으로 올바른 목표 스타일 문장 생성
- 방법(4가지)
- RETRIEVEONLY
- 검색된 문장을 그대로 출력 → 문법과 목표 스타일은 일치하지만 content 유사성 저하
- TEMPLATEBASED
- 원본 문장에서 삭제된 attribute marker를 검색된 문장의 attribute marker로 대체
- 단순 대치이므로 문법적으로 올바르지 않을 가능성 존재
- DELETEONLY
- content를 RNN으로 임베딩하고, 목표 스타일의 임베딩과 연결하여 RNN decoder로 문장 생성
- DELETEANDRETRIEVE
- 목표 스타일 대신 검색된 문장의 attribute marker를 사용
- 문맥에 맞는 attribute를 사용하고 문법적인 오류를 줄일 수 있음
- DELETEONLY에서는 delete 이후 content를 목표 스타일(e.g., "negative")과 임베딩을 연결했다면,
- 여기서는 동일하게 RNN을 이용하지만 검색된 문장의 attribute marker(e.g., "barely used")를 이용
- RETRIEVEONLY
Training

- DELETEONLY: auto-encoder 방식으로 스타일을 제거한 content와 스타일이 주어지면 원본 문장을 다시 생성하도록 학습
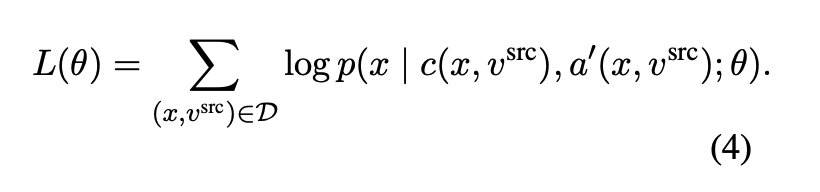
- DELETEANDRETRIEVE
- denosing auto-encoder 방법
- 학습하는 동안 각 attribute marker를 무작위로 변경하여 noise를 적용
- 동일한 attribute marker와 word-level edit distance 1의 다른 무작위로 선택된 attribute marker로 replace → $a'(x, v^{src})$ 생성
- 이를 통해 모델이 다양한 입력에 유연하게 대응하도록 함
Experiments
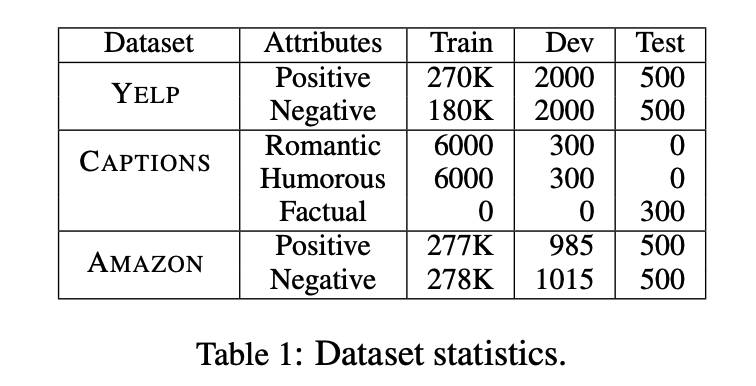
1. Datasets
2. Results
- Human Evaluation

- Automatic Evaluation
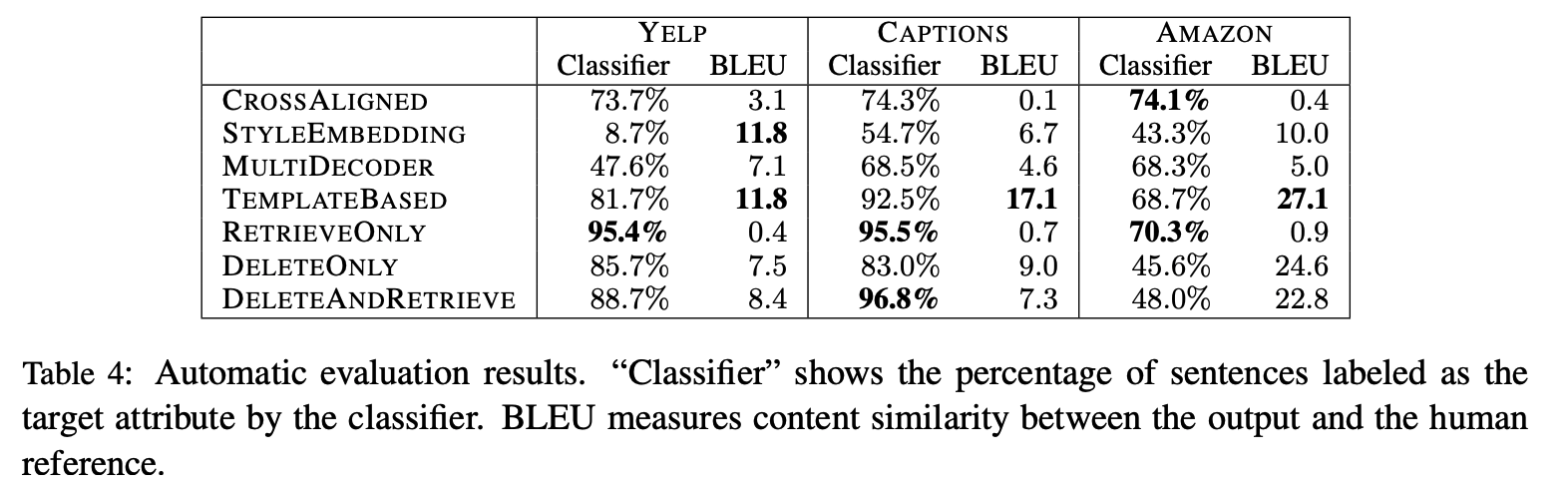
- 두 평가지표의 결과를 비교하였을 때, Amazon 데이터셋에서 정성 평가와 classifier간의 관련성이 없음을 확인
- 자동적으로 평가하기 때문에 BLEU의 경우에도 문법적인 오류가 많이 발생하는 TEMPLATEBASED가 더 높게 나옴
'딥러닝 논문 리뷰 > Text Style Transfer' 카테고리의 다른 글
| [논문리뷰] Style-Specific Neurons for Steering LLMs in Text Style Transfer (0) | 2024.12.12 |
|---|---|
| [논문리뷰] Politeness Transfer: A Tag and Generate Approach (0) | 2024.11.19 |
| Text Style Transfer 텍스트 스타일 변환 데이터셋 조사 (3) | 2024.11.18 |
| Text Style Transfer 텍스트 스타일 변환 목표, 방법론 정리 (0) | 2024.11.18 |


