- 논문: https://arxiv.org/pdf/2004.14257
- 소스코드: https://github.com/tag-and-generate/
- 이 논문은 문장의 의미를 유지하면서 공손하지 않은 문장을 공손한 문장으로 변환하는 태스크 수행
- 이를 위해 공손한 정도를 자동으로 라벨링한 139만 개 이상의 문장으로 된 데이터셋 공개
- 공손 변환을 포함하여 여섯 가지 스타일 변환 태스크에 대해 "Tag and Generate" 파이프라인 설계
- 이 파이프라인은 tagger와 generator라는 두 가지 모듈로 구성
- tagger: 원본 스타일의 단어나 구를 식별하여 [TAG] 토큰으로 대체
- generator: tagger의 출력을 입력으로 받아 대상 스타일의 문장 생성
- 기존에 입력 문장에 대하여 수정이 필요한 부분을 guide하기 위해 tag를 부착하는 방식을 사용했던 터라, 읽어봄
- 다만 여기서는 tag가 markup language의 tag가 아니라 토큰이라는 점이 차별점
Tag and Generate

- 텍스트 스타일 변환을 위해 두 단계로 구성된 파이프라인
1. Estimating Style Phrases(스타일 구 추정)
- 각 스타일을 특정하는 구문 파악 필요 → n-gram if-idf 기반 접근 방식 제안
- 두 스타일 S1, S2에 해당하는 코퍼스 X1, X2가 주어졌을 때,
- 두 코퍼스에 존재하는 n-gram word w에 대한 확률 분포 계산
- 수식(1)은 스타일 S2의 i번째 문장에서 n−gram(w)의 if-idf 값
- 높을 수록 해당 n-gram(w)이 S2에서 더 자주 등장하고, S1에는 덜 등장
- 수식(2)는 (1)을 smoothing하고 정규화
- 각 n-gram이 target style marker일 확률을 나타내는 확률 분포
- 특정 n-gram(w)의 (1) 값이 전체 n-gram들의 각 값에서 차지하는 비율
- S2 style marker 집합은 (2)가 특정 임계값 k 이상인 구문 w로 구성
2. Style Invariant Tagged Sentence(스타일 불변 태그 생성)
- 목표: source 문장에서 스타일 속성을 제거하고 target 스타일의 문구가 삽입될 위치를 나타내는 [TAG] 토큰으로 대체하여 스타일과무관한(invariant) 태그 문장 생성
- 과정
- tagger model 은 1에서 얻은 스타일 어휘로 style marker를 식별하고, 이를 [TAG] 토큰으로 replace or add
- task, source 문장에 따라서 두 가지 tagger model 중 하나 선택
- replace, add tagger model은 독립적으로 학습
- Replace-Tagger: source 문장에 style attribute marker(a(x(1)i))가 존재하는 경우 사용(e.g., sentiment)
- Add-Tagger: target style marker가 삽입될 적절한 위치에 [TAG] 토큰을 추가(e.g., politeness)
- sentiment는 "dislike", "hate"와 같이 스타일을 나타내는 특정 어휘가 분명한 반면에,
- politeness는 오히려 "please"와 같이 추가 되어야 하는 경우가 더 많고 그 기준도 불명확함
- 모델을 학습하는 데이터는 [TAG] 토큰으로 대체될 style marker samples을 포함
- [training] Replace-Tagger
- replace-tagger는 거의 모든 문장에 attribute marker가 존재하는 sentiment task에 적합
- 이 경우 학습데이터는 입력이 X1이고, 출력이 {z(xi):x(1)i∈X1}인 쌍으로 구성
- 주어진 입력 문장에 대해 가장 가능성이 높은 style invariant 문장을 생성하도록 학습
- [training] Add-Tagger
- add-tagger는 style neutral 문장에서 target style로 변환이 되어야 하는 경우를 위해 설계
- X1: style neutral sentences / X2: target style sentences
- source 문장에서는 제거할 attribute marker가 없으므로 tagger는 target style의 style word([TAG])를 추가하는 법 학습
- 학습데이터는 입력이 {x(2)i∖a(x(2)i):x(2)i∈X2}, 출력이 {z(xi):x(2)i∈X2}
- 기본적으로 입력의 경우, target style S_2에서 스타일 구문을 명시적으로 제거
- 출력의 경우 동일한 구문을 [TAG] 토큰으로 바꿈
- 이를 위해서 style neutral한 문장은 학습데이터로 사용하지 않고 오로지 target sentence만을 사용
| Figure 4: Creation of training data for add-tagger | loss objective |
|
 |
3. Style Targted Generation
- [TAG] 토큰을 포함하는 style invariant 문장을 입력으로 받아, [TAG] 토큰을 target style의 단어로 대체하는 문장 생성
- [TAG] 토큰은 target style을 특징짓는 문구 집합(Γ2)에서 샘플링된 단어로 대체
- loss function
- Xv: target style Sv (v=1 또는 2)의 문장 집합
- θg: generator의 파라미터
- x(v)i: target style Sv의 문장
- 주어진 style invariant tag sentence에 대해 가장 가능성이 높은 target style sentence를 생성하도록 학습
Experiments and Results
- Ours: tagger와 generator modules을 학습하기 위해 4-layerd transformers 사용
- 비교 모델
- DRG(Delete, Retrieve and Generate): 스타일 마커를 삭제하고 타겟 스타일 문구로 대체
- BST(Back-translation): 역번역을 통해 스타일 변환
- CAE(Cross Alignment): 병렬적이지 않은 텍스트에서 스타일 변환 수행
- 데이터셋
- politeness transfer: Enron corpus
- captions: 이미지 캡션을 사실적, 로맨틱, 유머러스로 분류한 데이터셋
- sentiment transfer: yelp, amazon
- gender: yelp 데이터셋에서 저자의 성별을 레이블링한 데이터셋
- political: Voigt et al.(2018)에서 공개한 데이터셋
- 평가지표
- Acc: target style classifier가 생성된 문장을 target domain으로 분류한 비율
- Content preservation: BELU-self, BLEU-ref
- ROUGE: 요약에 사용되는 지표
- METEOR: 동의어 및 어간 형태를 고려하여 의미적 유사성을 측정하는 지표
- 보통 스타일 변환 태스크 역시, 스타일 어휘의 범위가 넓어서 classifier나 embedding 비교도 많이 사용
- human evaluation
- 일부 결과
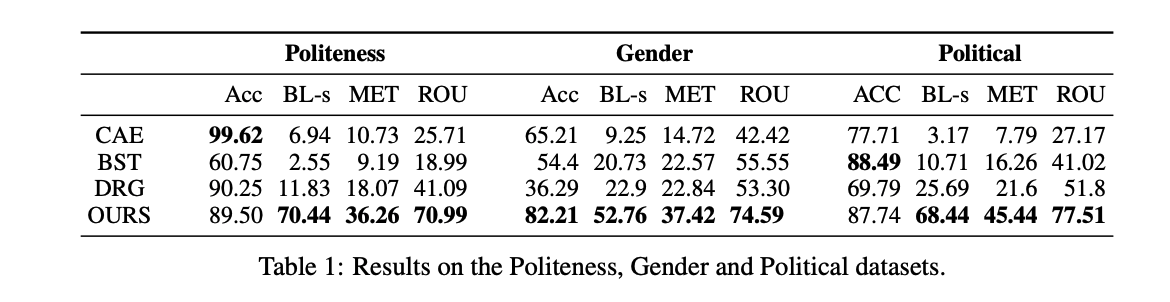
- 스타일 변환을 위해 [TAG] 부분만 수정하는 식이므로 self-BLEU가 다른 모델보다 높은 것을 확인 가능
- 내용 보존성 측면에서 좋음
- 한계점
- 자동 평가의 한계가 존재하며, task에 따라서 tagger 변형 선택의 중요성 고려 필요
'딥러닝 논문 리뷰 > Text Style Transfer' 카테고리의 다른 글
| [논문리뷰] Style-Specific Neurons for Steering LLMs in Text Style Transfer (1) | 2024.12.12 |
|---|---|
| [논문리뷰] Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Tran (0) | 2024.11.20 |
| Text Style Transfer 텍스트 스타일 변환 데이터셋 조사 (3) | 2024.11.18 |
| Text Style Transfer 텍스트 스타일 변환 목표, 방법론 정리 (0) | 2024.11.18 |


